在Linux下透過ollama直接跑LLM大型語言模型:以llama3為例
總不能永遠活在Docker下,今天的需求是單獨透過一台Linux安裝Ollama,執行Meta LLAMA3並對外提供API服務。
在Linux下安裝Ollama
Step 1. 切到root權限
sudo -i
Step 2. 把所有該更新的檔案都更新一遍。
apt update
apt upgrade -y
Step 3. 安裝Ollama。
curl -fsSL https://ollama.com/install.sh | sh
Step 4. 確定Ollama運行無誤:因為沒有瀏覽器,所以透過curl來進行確認。
curl http://localhost:11434
如果出現Ollama is running就確定沒問題了。
Step 5. 開啟外部網路監聽。
如果只有在localhost才能用就太可惜了,因此我們可以到下列網址進行脫離本機的設定:
nano /etc/systemd/system/ollama.service
在下列區塊下新增一行設定,因為我只有一塊網卡所以就偷懶設定全域監聽0.0.0.0,如果你只想要綁定到某一組IP就請自行指定:
[Service]
Environment="OLLAMA_Host=0.0.0.0"
設定儲存好後,可以透過下列指令重啟服務(其實重開機會更快一點):
systemctl daemon-reload
systemctl restart ollama
完成後就到確定可連線到192.168.1.10這台Linux的電腦,透過圖形介面瀏覽器開起來看一下是否也有出現Ollama is running,例如:http://192.168.1.10:11434。
透過Ollama下載LLM大型語言模型
這次的目標對象是LLAMA3模型,從這個網址https://ollama.com/library觀察到Ollama已經開始提供llama3模型(Models)了,因此輸入指令:
ollama pull llama3
檔案有點大,所以要等一下才會下載完成。
在Console透過Ollama執行LLM大型語言模型
先透過下列指令,確定當前Ollama擁有哪些LLM大型語言模型?
ollama list
挑選你要運行的大型語言模型後,就可開始執行了,例如:
ollama run llama3
透過API調用Ollama執行LLM大型語言模型
依據Ollama文件Generate a completion,使用JSON透過API送要求請LLAMA3分析處理,因為懶得再寫程式碼所以直接用POSTMAN驗證:
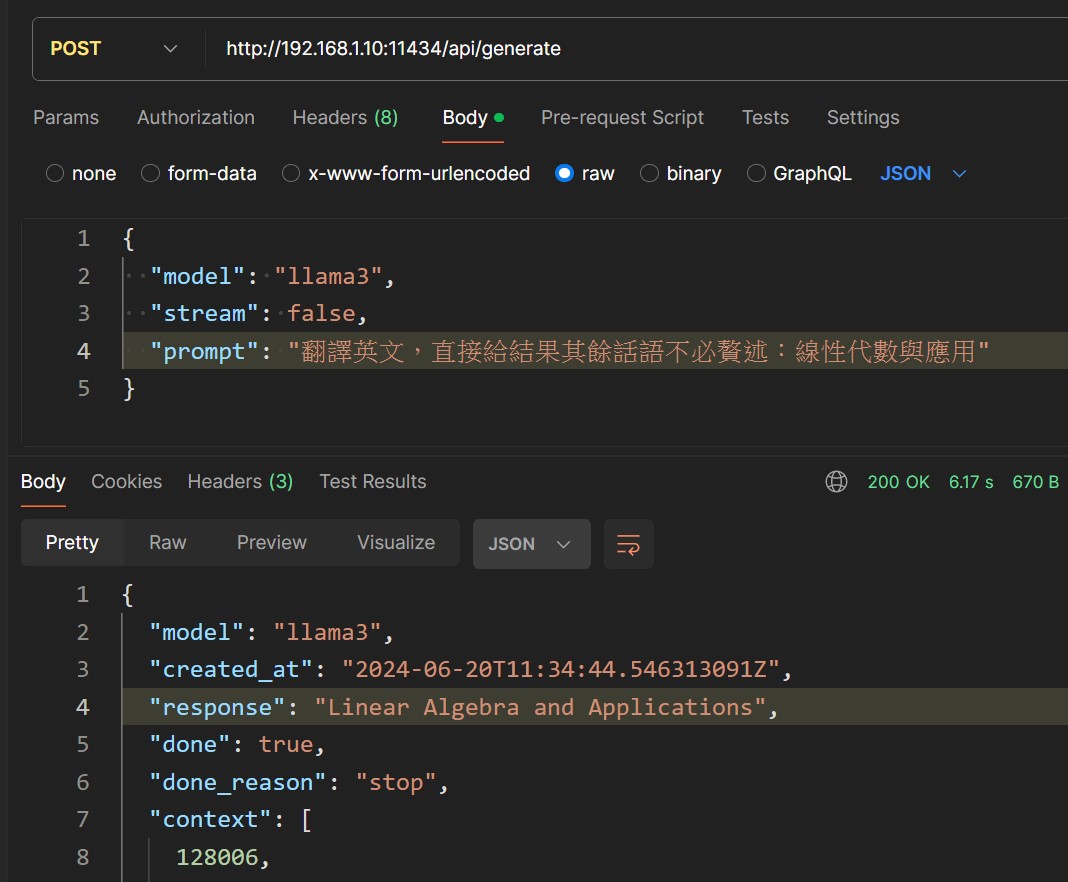
看起來翻譯品質還是不錯的喔!
相關連結
- 不使用GPU在本機跑LLM大型語言模型:以TAIDE為例(Docker)
- 透過ollama直接跑LLM大型語言模型:以llama3為例(Docker)
- 在Linux下透過ollama直接跑LLM大型語言模型:以llama3為例