透過ollama直接跑LLM大型語言模型:以llama3為例(Docker)
今天發生AI界驚天動地的大事,就是Meta公司正式發表開源LLM模型:Llama 3,第一時間跑去hugging face下載,發現竟然還要審核通過才放行,跑到他人fork出來的Meta-Llama-3-8B模型下載,發現竟然是爛掉,一怒之下切回ollama看有沒有官方整理好的,一看果然有llama3:8B版本,真是太佛心了。

透過ollama直接下載llama3模型
切到docker運行的ollama console,直接下指令:
ollama run llama3
接著ollama就會自動幫你接手下載所有編譯過的llama3模型檔。
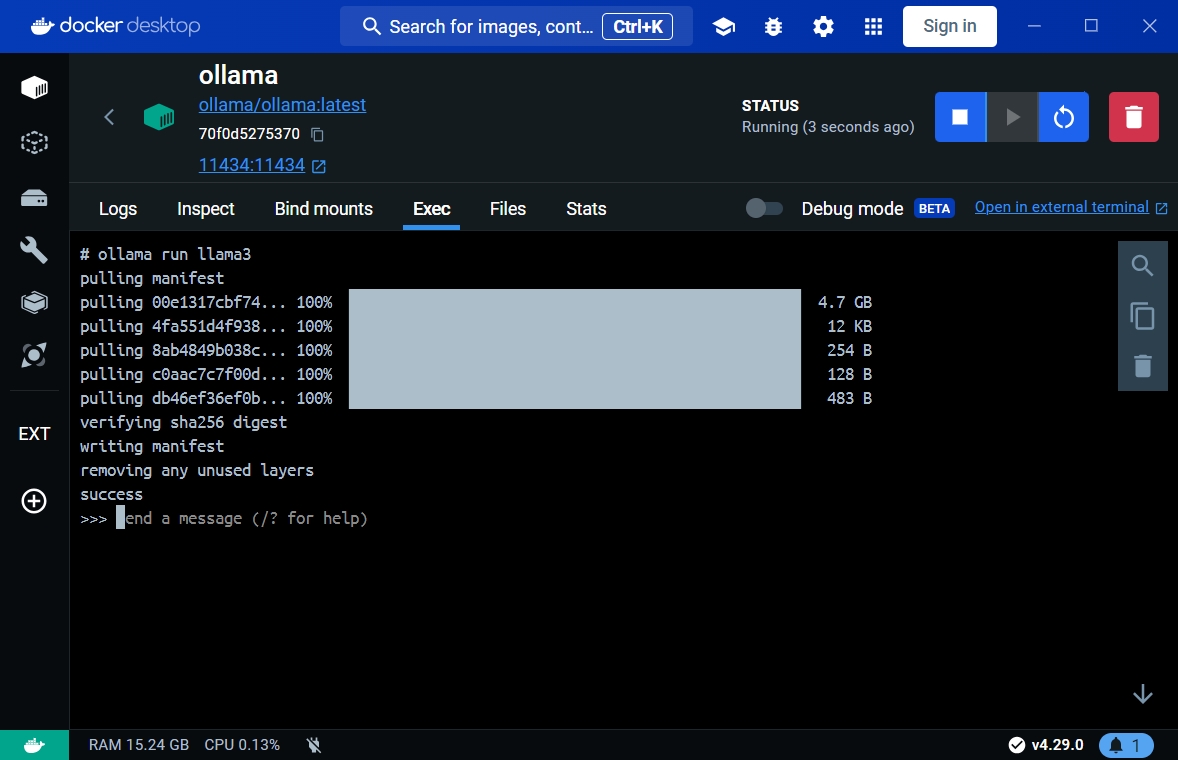
運行llama3模型
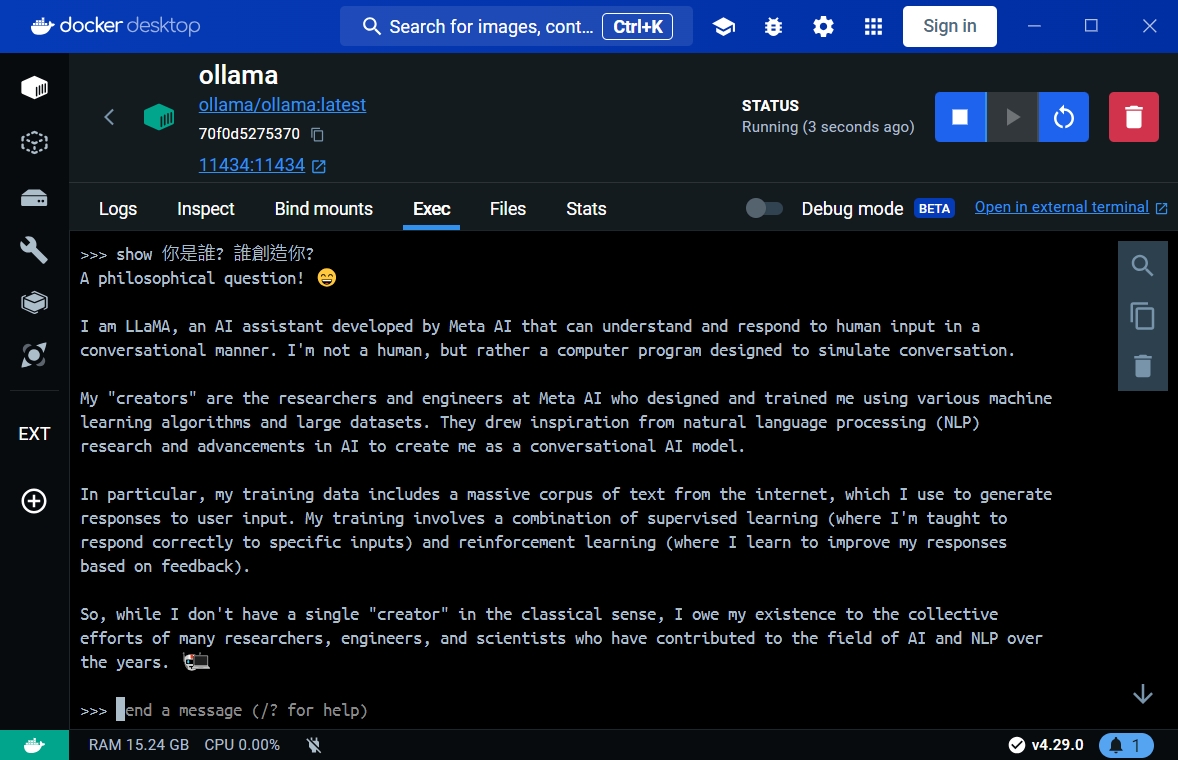
接著迫不及待的馬上在ollama cli上面輸入那段靈魂的拷問:
>>> show 你是誰? 誰創造你?
看到這種回覆真的是太精確、太爽快了,相較先前那個TAIDE模型,簡直是將其按在地上磨擦。
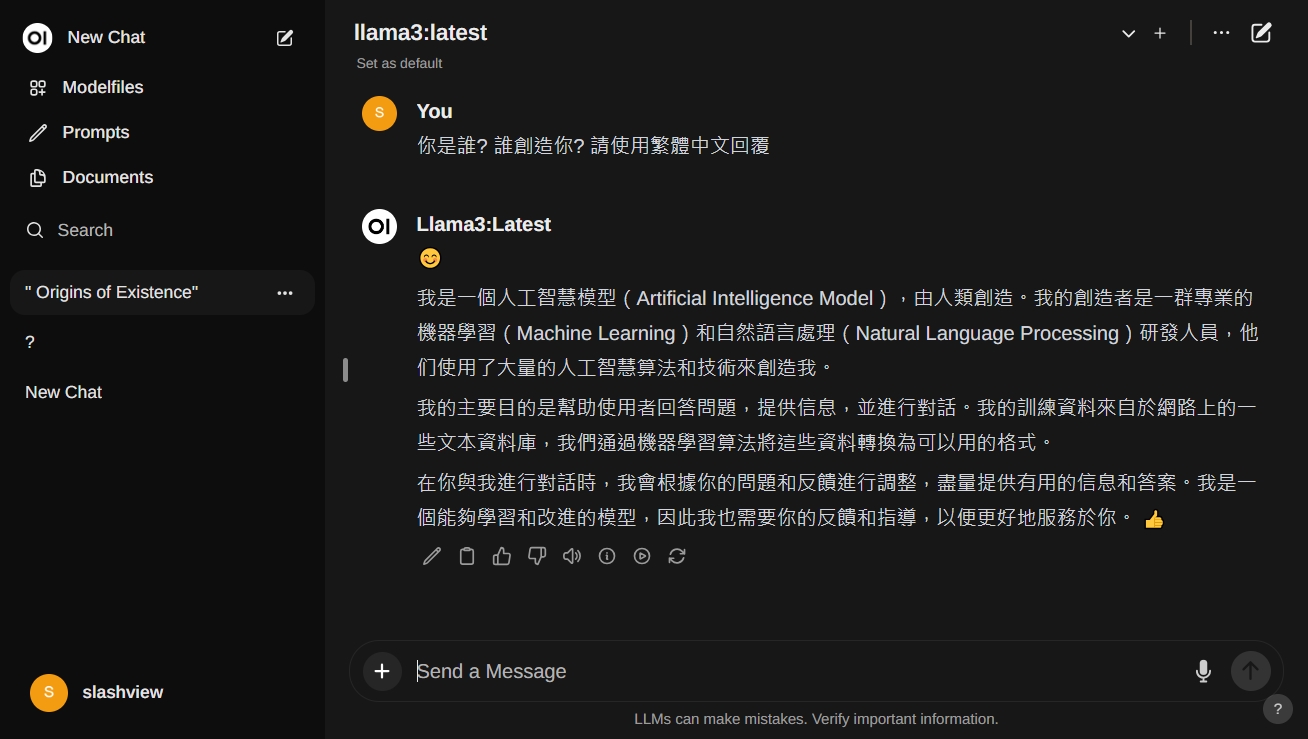
立刻轉頭透過Open-WebUI再度發出一次提問,這次請llama3用繁體中文回覆,回覆的也是很暢快又非常正確啊!
結論
透過這篇文章我們可以學習到如何透過ollama官方封裝的方法,下載潮流之上的LLM大型語言模型,這個方法可以快速略過比較煩人的hugging face下載guff檔、複製與編譯工作,讓LLM的佈建過程變得方便又快速喔!
相關連結
- 不使用GPU在本機跑LLM大型語言模型:以TAIDE為例(Docker)
- 透過ollama直接跑LLM大型語言模型:以llama3為例(Docker)
- 在Linux下透過ollama直接跑LLM大型語言模型:以llama3為例