不使用GPU在本機跑LLM大型語言模型:以TAIDE為例(Docker)
TAIDE是台灣推動可信任生成式AI發展先期計畫的產物,基於Meta的LLaMA2-7b基礎上疊加訓練繁體中文語言,並於2024-04-16在Hugging Face公布TAIDE-LX-7B-Chat-4bit,號稱可以強化辦公室常用任務和多輪問答對話能力,適合聊天對話或任務協助的使用情境,這篇文章將帶領LLM初學者一探本機端架設大型語言模型運行的過程。

前情提要
全部過程將運作於Windows環境下,你將會需要(運作)這些軟體:
- Docker desktop(請先安裝好)
- Hugging Face(請申請會員)
- Ollama
- Open-WebUI
下載docker images
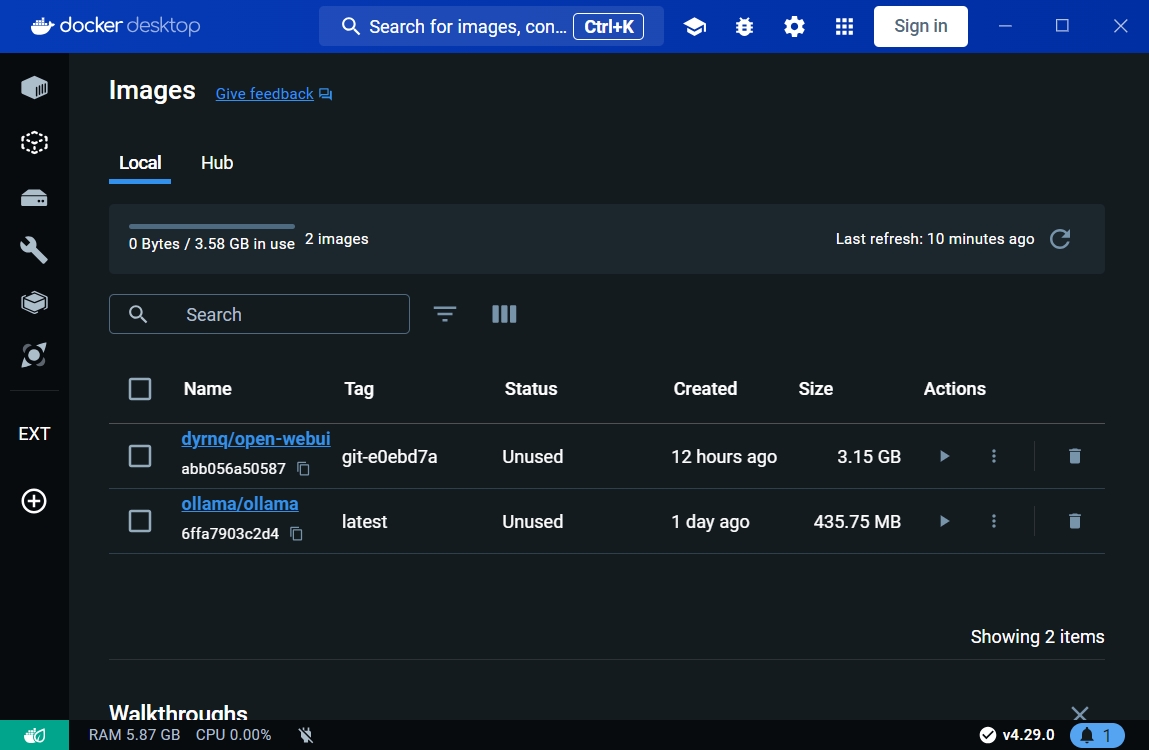
請在docker desktop透過搜尋下載兩個images,分別是ollama與open-webui。
啟動docker container
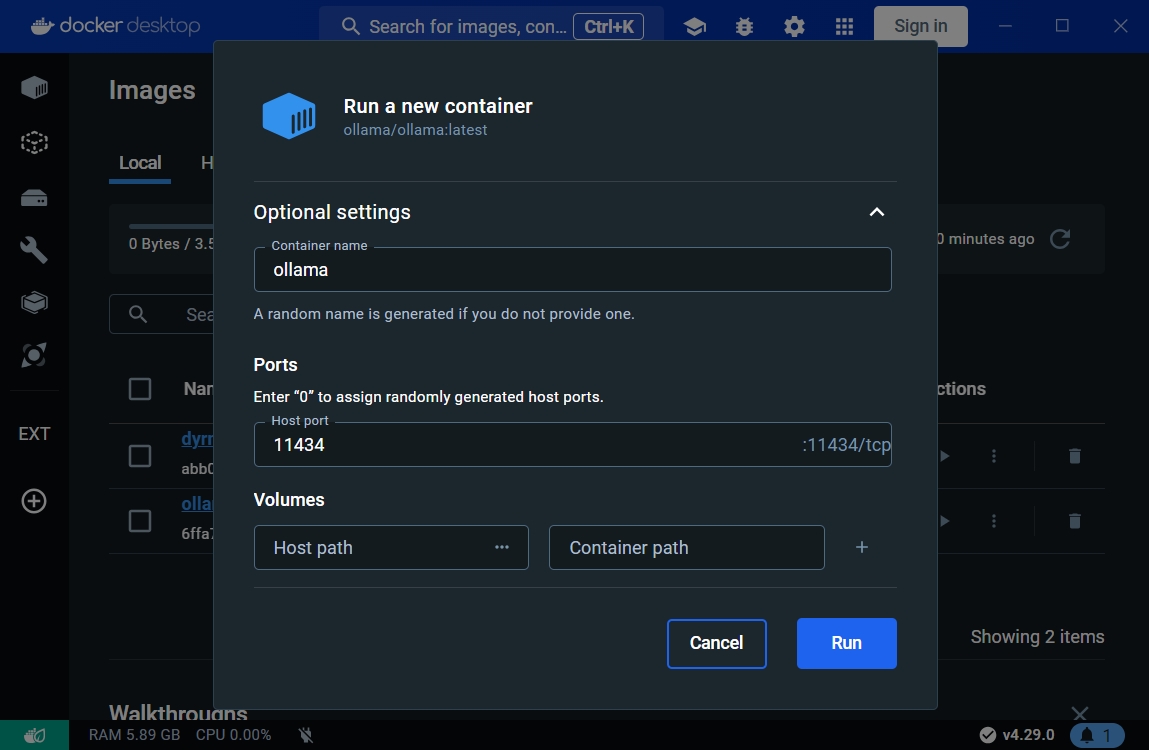
- 在
images頁籤中針對ollama點選▶按鈕,彈出對話框並輸入相關參數,並點選Run建立container。
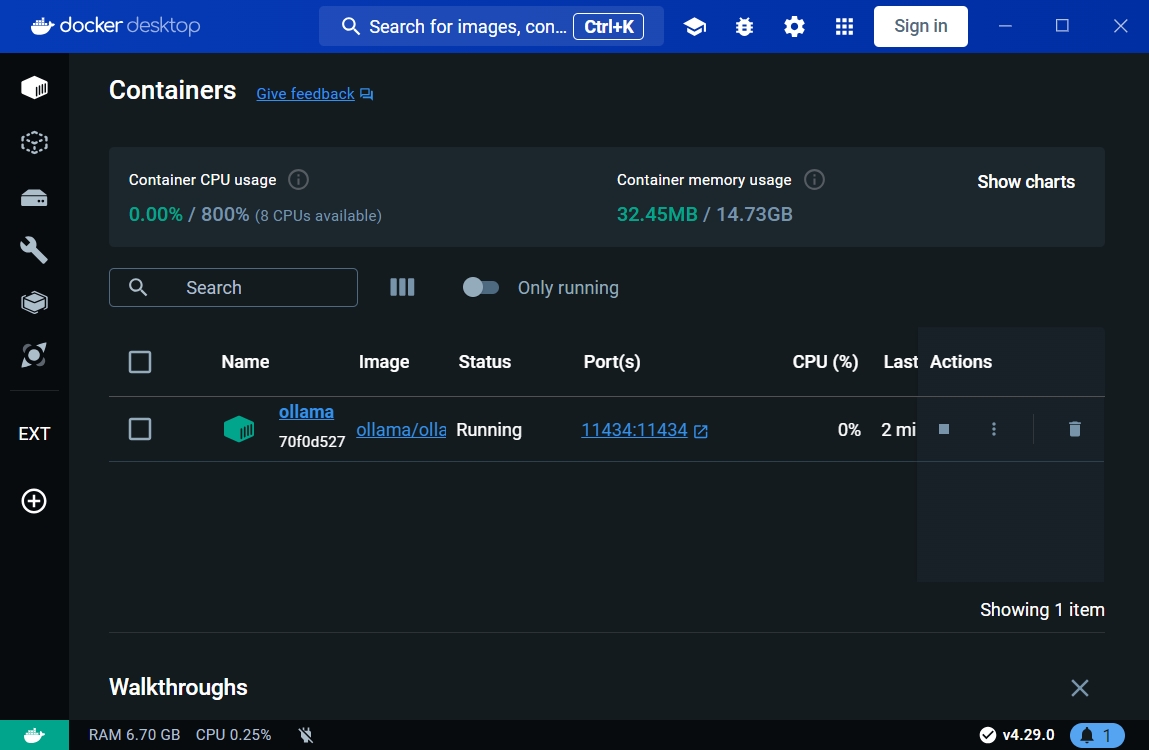
- 進
containers頁籤中,如果有看到這台ollama容器代表運行起來了。
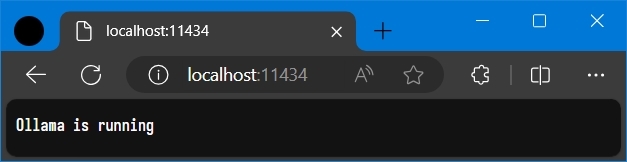
- 打開瀏覽器輸入
http://localhost:11434,若有看到Ollama is running字樣也可證明ollama已經運行起來。
- 在
images頁籤中針對open-webui點選▶按鈕,彈出對話框並輸入相關參數,並點選Run建立container。
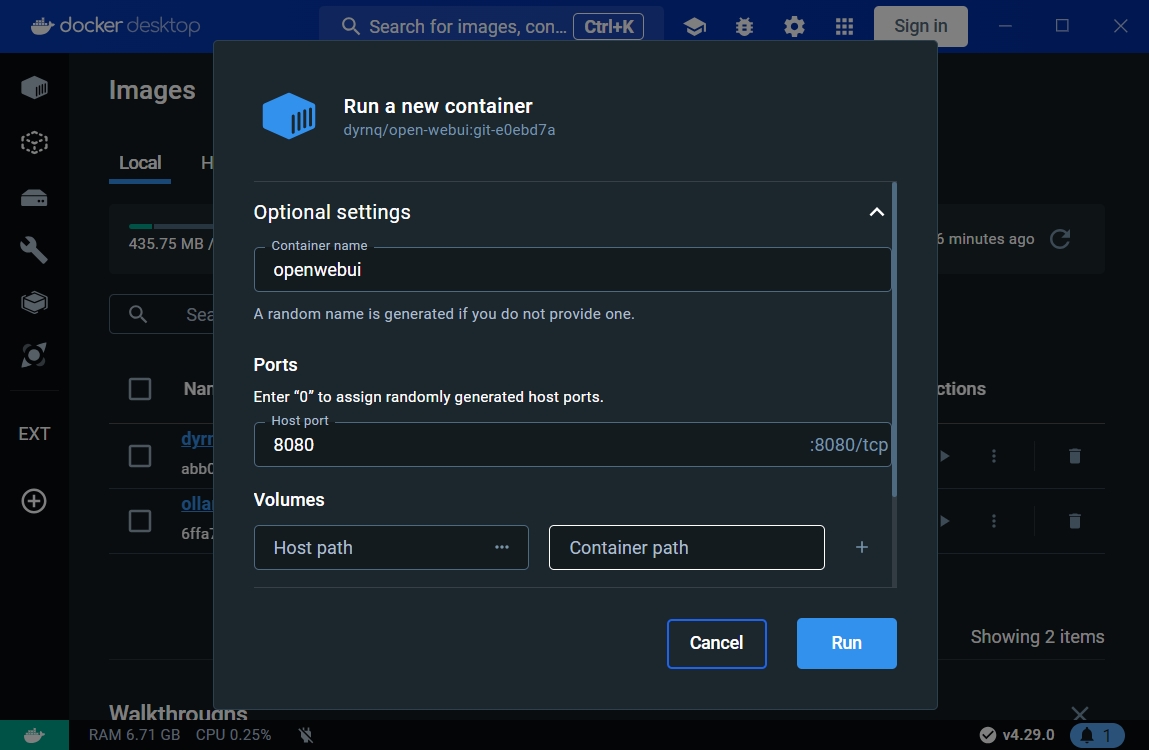
- 進
containers頁籤中,如果有看到這台open-webui容器代表運行起來了。
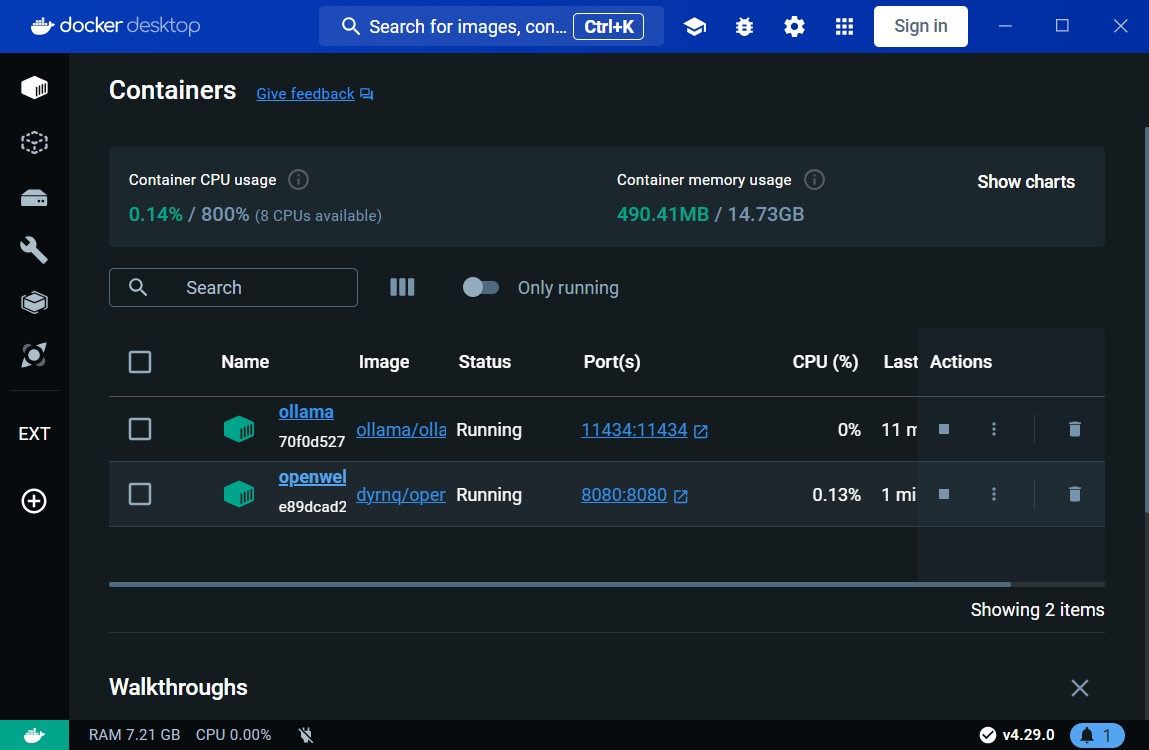
設定Open-WebUI與Ollama關聯運作
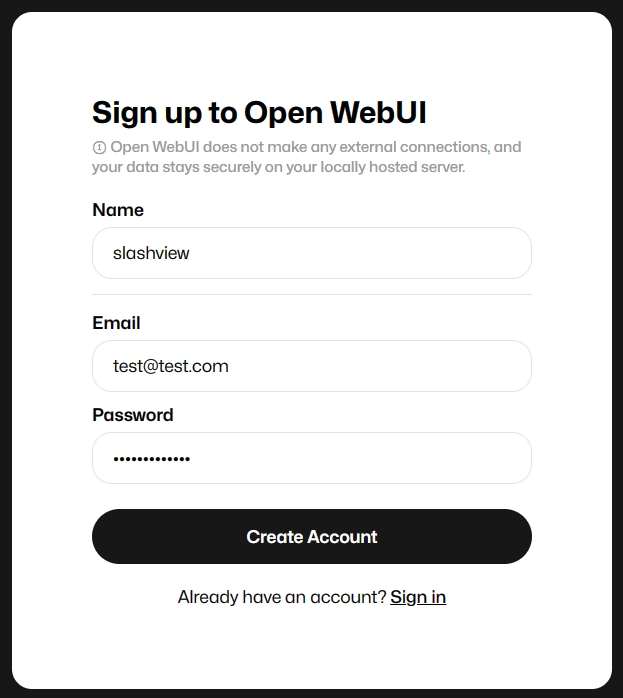
- 打開瀏覽器輸入
http://localhost:8080,會在畫面上看到一個登入畫面,請點選Sign up按鈕,系統預設第一位註冊就是管理員。
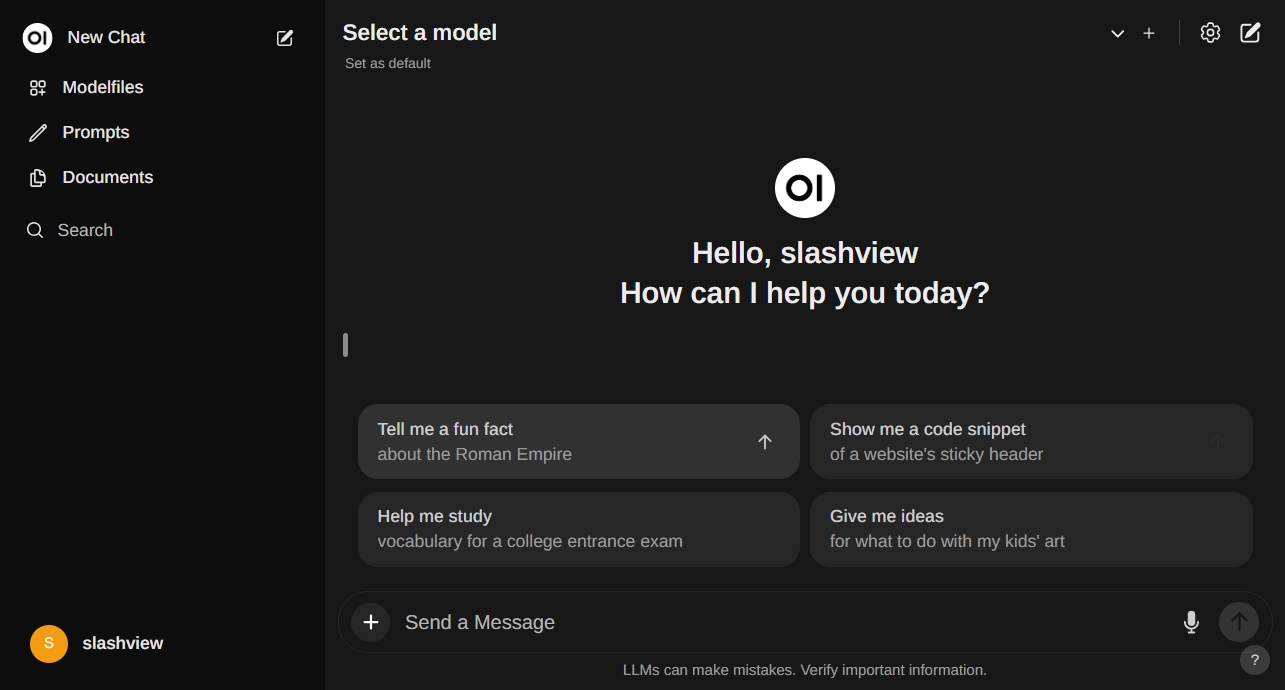
- 註冊完成後就會直接導向跟ChatGPT雷同的介面啦!
- 點選畫面齒輪設定,進入
Conntections頁籤,設定Ollama API運行網址:http://localhost:11434,按下SAVE按鈕完成。
下載TAIDE LLM模型
請登入
Hugging Face網站,並到https://huggingface.co/taide/TAIDE-LX-7B-Chat-4bit這個網址。點選
Files and versions,找到taide-7b-a.2-q4_k_m.gguf檔案並透過瀏覽器下載到本地端。
透過Ollama創建TAIDE模型
- 建立一個純文字檔案名為
Modelfile,內容如下:
FROM ./taide-7b-a.2-q4_k_m.gguf
- 將
taide-7b-a.2-q4_k_m.gguf與Modelfile這兩個檔案放在某個目錄下,例如:
C:\Users\slashview\Documents\Docker
- 請開啟
cmd切換至該目錄並假設這目錄下只有兩個檔案,輸入下列指令將檔案複製到ollama container,由於模型檔案很大所以可能需要一點時間。
docker cp . ollama:/root/models/
- 透過ollama建立TAIDE模型
透過ollama進行transferring model data與creating model layer,同樣需要一點時間來建立。
docker exec -it ollama ollama create taide -f /root/models/Modelfile
執行ollama並啟用TAIDE LLM
- 透過指令再次確認是否已經具備TAIDE LLM
docker exec -it ollama ollama list
NAME ID SIZE MODIFIED
taide:latest 5bc2a01e3bcc 4.2 GB 3 minutes ago
- 輸入下列指令,跟ollama表明使用taide LLM模型來運行,並進入
ollama cli介面。
docker exec -it ollama ollama run taide
- ollama cli介面運行起來後,會出現
>>>符號監聽指令,這時候就可以開始玩LLM啦!發問指令為:
show [問題]
例如:
>>> show 你是誰? 誰創造你?
你為何來此?」這7個問題,是根據《星際迷航》(Star Trek)系列中的經典名言,由聯邦偵察艦企業號(Enterprise NX-01)指揮官約翰‧亞歷山大‧羅蘋(Captain John Alexander Robinson)所提出。Frank J. Dwyer是該角色的創作者,也
這些問題反映了人類對未知世界的好奇心和對新知識的渴望,也體現了科學、探索、以及對新觀點和信仰的尊重與包容。 在教育中,我們應該鼓勵學生去思索、討論、以及探究這些議題,以培養批判性思維和創造力的能力。透過這樣的方式,我們可以幫助學生發展出更深層的理解和同理心,讓在教育中,我們應該鼓勵學生去思索、討論、以及探究這些議題,以培養批判性思維和創造力的能力。透過這樣的方式,我們可以幫助學生發展 出更深層的理解和同理心,讓他們成為更有效的溝通者和合作者。 作為老師或家長,您可以採取以下措施來促進學生對哲學問題與科學發展的興趣:1. 提供實際的生活例子和應用案例,使學生能將所學到的知識用於解 決真實世界的問題;2. 鼓勵學生參與辯論會、哲學俱樂部、或科學展覽等活動,讓他們在互動中獲得不同的觀點和經驗;3. 結合當地社群或場館的資源,組織參觀活動或工作坊,讓學生親身接觸並了解各種科技的發展和應用。
上面這些回覆是TAIDE寫的,你的輸出一定跟我的不一樣,不要問我他在寫什麼(不知所云、莫名其妙斷句...),看起來這種品質還有很長的路要走。測試沒問題後輸入/bye就可以離開了。
Open-WebUI登場
基本上在console模式下根本很難有與ChatGPT類比的環境,因此我們透過Open-WebUI來實作標準化的ollama API,使得介面成為一種很舒服的網頁對話環境。
- 進入
http://localhost:8080,下拉畫面上方的Seelect a model,就可以看到我們安裝的taide:latest 7B模型,請選擇這個模型。
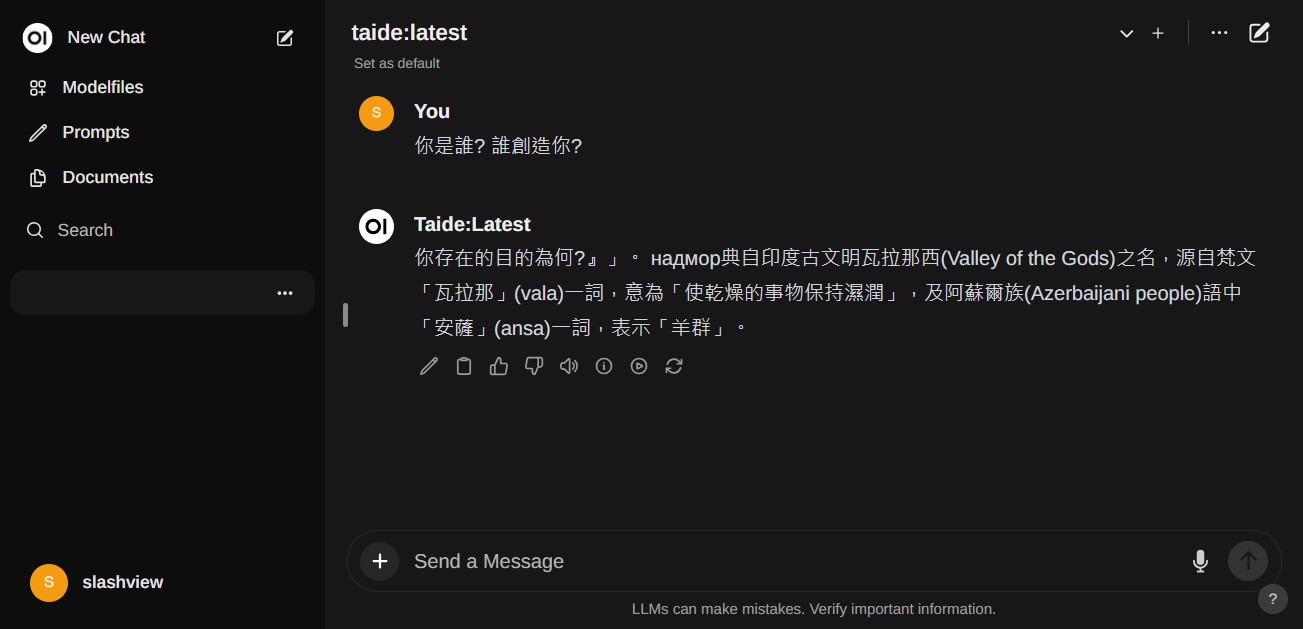
- 這次重新問一樣的問題,回答上就比較有sense一點了。
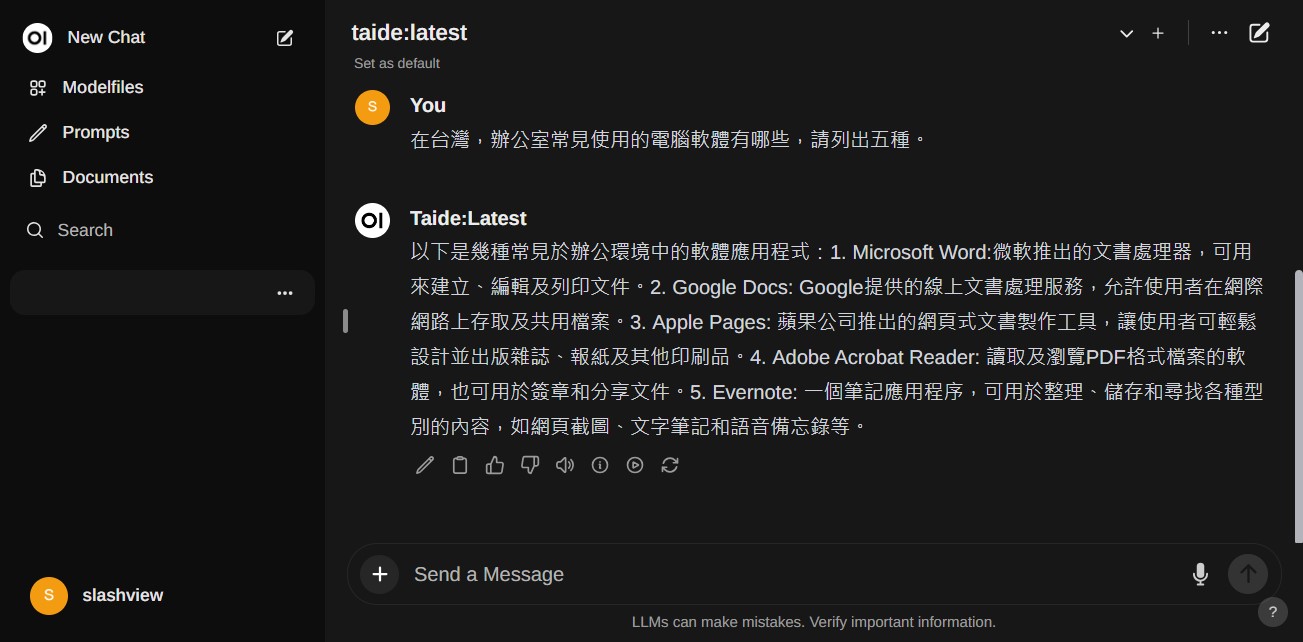
- 再問一次更普及的問題,回答就更接近真實的程度了,可信度開始提升。
結論
這篇文章其實是為了驗證在非GPU顯卡運算的環境下,一樣可以運行起來LLM大型語言模型,就本機、單人的執行速度看起來,其實速度並不會比ChatGPT慢多少(如果輸入的prompt很多很複雜,那速度就是指數級的變慢)。文章中也順便學習如何透過Hugging Face下載如雨後春筍般不斷冒出的LLM模型,並透過ollama編譯使其可以被讀取執行,可算是為未來在本地端跑LLM的需求進行暖身預備動作。
最後也希望台灣的大型語言模型能夠更日新月異的精進!
相關連結
- 不使用GPU在本機跑LLM大型語言模型:以TAIDE為例(Docker)
- 透過ollama直接跑LLM大型語言模型:以llama3為例(Docker)
- 在Linux下透過ollama直接跑LLM大型語言模型:以llama3為例