如何在在Excel中找出BIG5的使用者造字字元?
今天收到了一個難題,就是如何在Excel的某姓名欄位中,找出該姓名中是否有出現BIG5的造字字元(使用者造字文字),由於敝人一向都是走程式設計,完全沒有再用Excel,當下腦袋是一片空白,只好開始翻閱網路文章補充知識,但不幸的,並沒有太多的文章在討論這方面的事情。(都甚麼時代了還在用BIG5,改用Unicode不好嗎?)

所幸經過文章的翻閱時期,突然在腦中閃過曾經在倚天中文、Windows 95時期對於「造字程式」有一點依稀模糊的印象,好像起始是在那萬惡的「FA40」區,好,就以此為方向吧!首先先打開萬惡的造字程式,驗證一下自己的印象是否有誤?如下圖:
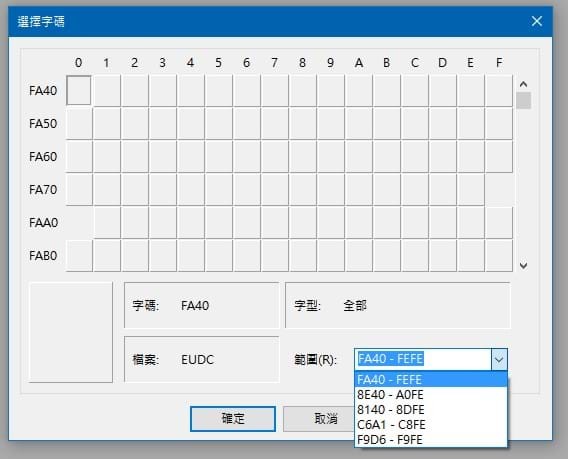
因此得到BIG5於Windows的造字區塊,總共被區分為四個區塊,以下列出BIG5與Unicode之於使用者自行造字之間的對照關係:
1. 「B」FA40-FEFE( 785字) → 「U」E000-E310( 785字)
2. 「B」8E40-A0FE(2983字) → 「U」E311-EEB7(2983字)
3. 「B」8140-8DFE(2041字) → 「U」EEB8-F6B0(2041字)
4. 「B」C6A1-C8FE( 408字) → 「U」F6B1-F848( 408字)
5. 「B」F9D6-F9FE( 41字) → 「U」F849-F8FF( 183字)
以上這是我在網路上找到的資料,我將其混合得到這個初步的結論。由這些對映可以發現其實Unicode跟BIG5在使用者造字區塊上無法完全對上,Unicode BMP(Basic Multilingual Plane)所訂定的Private Use Area可使用字元數目為6,400 code points。當然這個結論或對照表可能是錯誤的,歡迎懂這方面知識的網友分享一下,若敝人在日後有發現新的知識,也會隨時回來這一頁進行內容的更新。
※註:如果你用計算機去算BIG5的區間,例如FA40-FEFE,會得到錯誤的區間總量數字,因為中間有跳碼啊(EX: FA7E之後跳到FAA1、FAFF之後跳成FB40...),打開「造字程式」看畫面就知道我在說啥。
※Reference: 全字庫中文碼介紹
撰寫Excel判斷是否為使用者造字字元之函式(公式)
詢問一下之前的造字環境,得到業管單位只有使用到第一區塊,也就是FA40段,因此將FA40(HEX)轉換成十進制,也就是「64064(DEC)」。(所以其他的造字區識別,容我偷懶沒有實作)
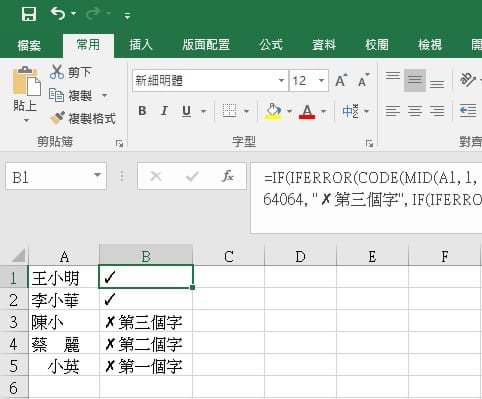
簡單的說,就是逐一取字,丟到CODE函式中進行轉碼,接著判斷是否大於等於64064,如果是的話,就斷定這個字元是使用者自行造字的字元,需要再進行進一步的處理。在這邊我只假設姓名最多四個字,再多的請自己修改公式了。
=IF(IFERROR(CODE(MID(A1, 1, 1)), 0) >= 64064, "✗第一個字", IF(IFERROR(CODE(MID(A1, 2, 1)), 0) >= 64064, "✗第二個字", IF(IFERROR(CODE(MID(A1, 3, 1)), 0) >= 64064, "✗第三個字", IF(IFERROR(CODE(MID(A1, 4, 1)), 0) >= 64064, "✗第四個字", "✓"))))
就這樣解完。套句現在熱門的語句:「寫的雖可恥但有用!」。畢竟,我可不願意在Excel上多花一秒的時間呢~
相關參考
- 列舉Windows作業系統下的造字檔內的所有文字(粗略版)
- 列舉Windows作業系統下的造字檔內的所有文字(精準版)
- 找出字串中隱藏的Big5造字字元,並用Unicode將其取代
- 如何在在Excel中找出BIG5的使用者造字字元?
- 更新造字字型檔(EUDC Fonts)的批次小程式
- Windows造字程式與字元對應表之字型無法匹配問題