統計:常態分佈、平均值、變異數與標準差
因為本身比較少接觸到統計方面的工作,又覺得有時候有需要用到這些知識,因此在非內行的情況下把一些以前就懂的知識,以及以前似懂非懂的知識,利用網路資源的尋找與瞭解將其串起來,如果有錯誤之處還請修正。
常態分佈(Normal Distribution)
首先遇到的是常態分佈,這個一直出現在我們生活週遭的統計分佈我想不會有人不知道吧!我們在小時候都有玩過打彈珠檯的遊戲,如果你懂的當燈號出現在中間就壓比較高倍,那就表示你很懂常態分佈啦!不過,通常中間的賠率是最低的(廢話)。還沒有辦法想像的,可以參考常在科學博物館出現的高登板(Galton Board),常態分佈的證據就是他發現的,當珠珠在一連串的(Level_N, 1/2)下決定,當Level_N趨近於無限大,高登板底部的結果分佈就會越接近常態分佈。詳見下面影片:
平均值(Means value, μ)
這個隨便一個小孩都知道,把所有的數列相加後,除以數列的總個數即可。
變異數(Variance, σ^2)
一個隨機變數的變異數,描述的是它的離散程度,也就是該變數離其期望值的距離。在統計學中,要估算一個變數的期望值時,經常用到的方法是重複測量此變數的值,然後用所得數據的平均值來作為此變數的期望值。變異數有個簡易口訣為:「平方的平均」減去「平均的平方」。
標準差(Standard Deviation, σ)
標準差定義為變異數的算術平方根,反映組內個體間的離散程度。標準差區分為母體(N)標準差以及樣本(n)標準差,只是母體永遠只是一個理想,例如你要調查台灣2300萬人口的平均身高,2300萬就是這個(N),但是你永遠辦不到,因為你永遠不可能真正的把2300萬人逐一的調查與量測。因此犧牲一個樣本數,增加了估計母體變異數的幅度,以避免抽樣時的誤差。標準差公式如下圖:
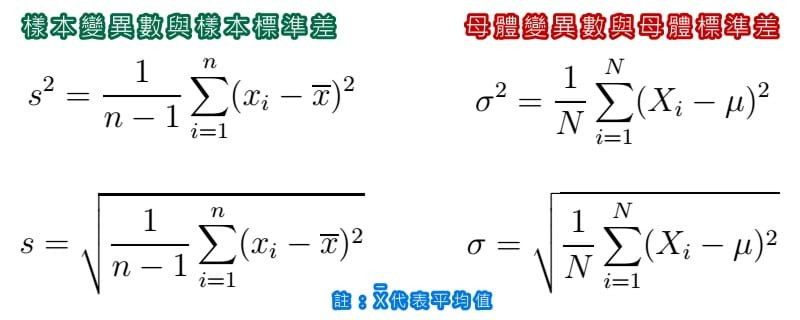
標準差與常態分佈
講了一大堆,標準差表現在常態分佈圖上,有其一定的比例,約略是「68, 95, 99.7」,也就是68%數值分佈在距離「平均值」有1個標準差之內的範圍,約95%數值分佈在距離「平均值」有2個標準差之內的範圍,以及約99.7%數值分佈在距離「平均值」有3個標準差之內的範圍。如下圖表示:
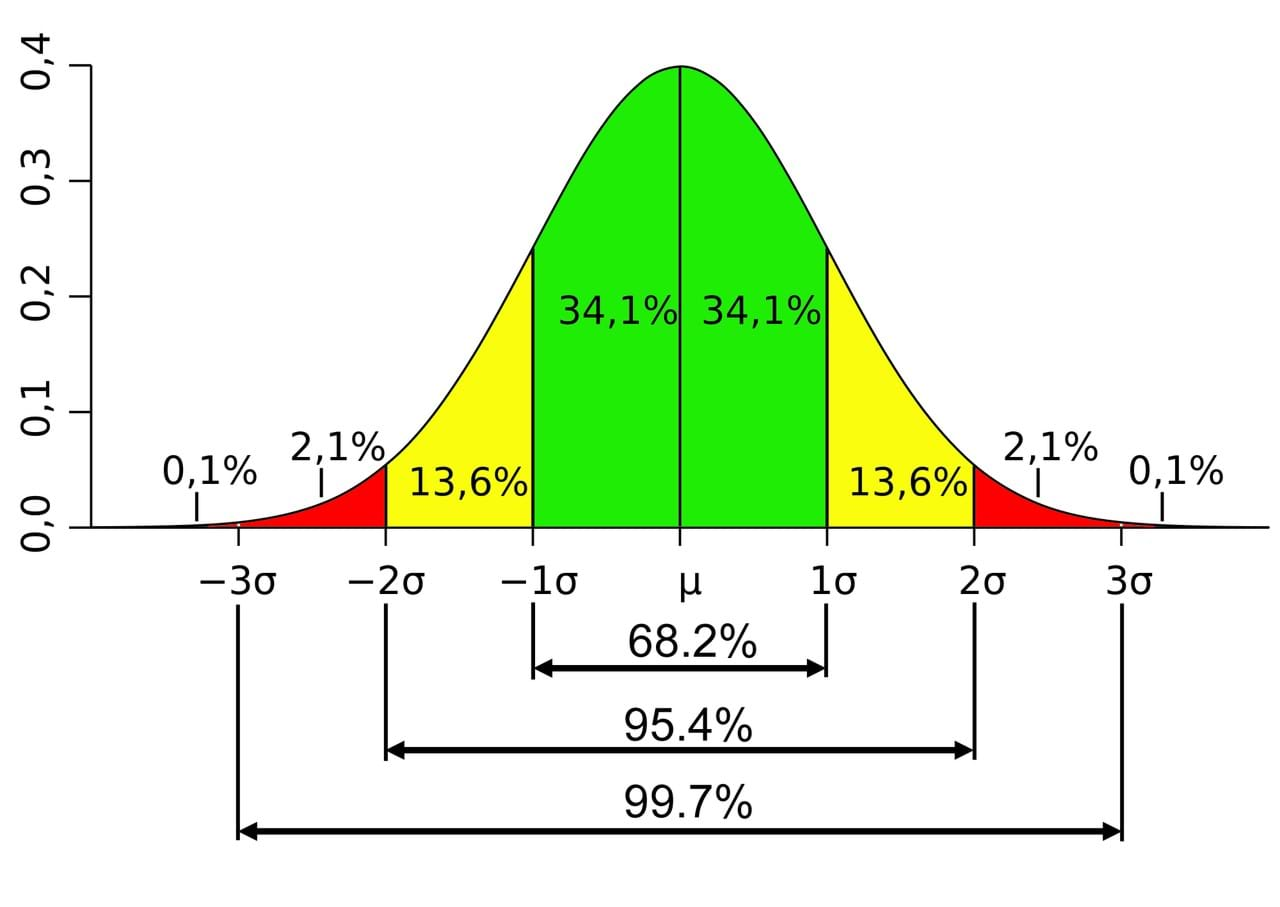
在品質的調控觀點來看,當你施行了某一種方法論,要驗證其效果,最好的方法是看數據是否大量的「改落在」1個標準差的範圍,用圖型的觀點來看,也就是會將這個倒鐘型常態分佈圖在靠近中央處越拉越高,兩邊變得越來越低,而不是永遠用簡單的平均折線圖來表示而已。
常態分佈與標準差之間的關係,也常常被用在很多領域的論述上,像Simon Sinek在進行偉大的領導者如何激勵行為很棒的演說時,提到的創意的散播法則不就是...。(微笑)
相關連結:
- 統計:常態分佈、平均值、變異數與標準差
- 統計:一個簡單的樣本變異係數的運算範例
- 統計:一個簡單的幾何平均數的運算範例
- 統計:比較平均數法、T檢定、F檢定、p顯著性之說明
- 統計:獨立樣本T檢定之適用範圍與SPSS操作
- 統計:成對樣本T檢定之適用範圍與SPSS操作
- 統計:單因子變異數分析One-Way ANOVA之適用範圍與SPSS操作
- 統計:多因子變異數分析Two-Way ANOVA之適用範圍與SPSS操作
- 統計:皮爾森相關係數Pearson Correlation之適用範圍與SPSS操作
- 統計:線性迴歸Linear Regression之適用範圍與SPSS操作