利用Html Agility Pack來擷取網站的HTML內文資料
這套Html Agility Pack(HAP)問世其實非常久了(我猜有十年了),但因為手頭上的工作沒有太多複雜的需求所以一直沒有真正的去使用他,中間也有其他的網頁內文擷取套件出現,但好像又默默地消失了,近日剛好手頭上有一個需求必須訪問HTML內容結構複雜的網站,必須取用該網頁內數個地方的資料,因此就把這套Html Agility Pack下載來用看看。嗯,不愧是.NET界網頁內容擷取的王者,果然一路順暢啊!
以下是安裝與網頁內容擷取範例:

安裝Html Agility Pack
Step 1. 至nuget下載HtmlAgilityPack套件。
nuget.exe install HtmlAgilityPack
Step 2. 將套件解壓縮後,把HtmlAgilityPack.dll參考到你程式碼的中,就這麼簡單。
使用Html Agility Pack
Html Agility Pack最強悍之處就是他可以接受HTML這種天馬行空的語言,無論你的結構要怎麼搞怎麼塞入他都可以順利地解析(parse)回來。另外他還有一個強大之處就是支援XPATH(XML Path Language)查詢語法,有了XPATH要尋訪到正確的節點再也不是難事了。
接下來示範一段小程式,示範怎麼去YAHOO氣象預報中拿到網頁的內容:
Step 1. 先確定YAHOO氣象預報的網址。
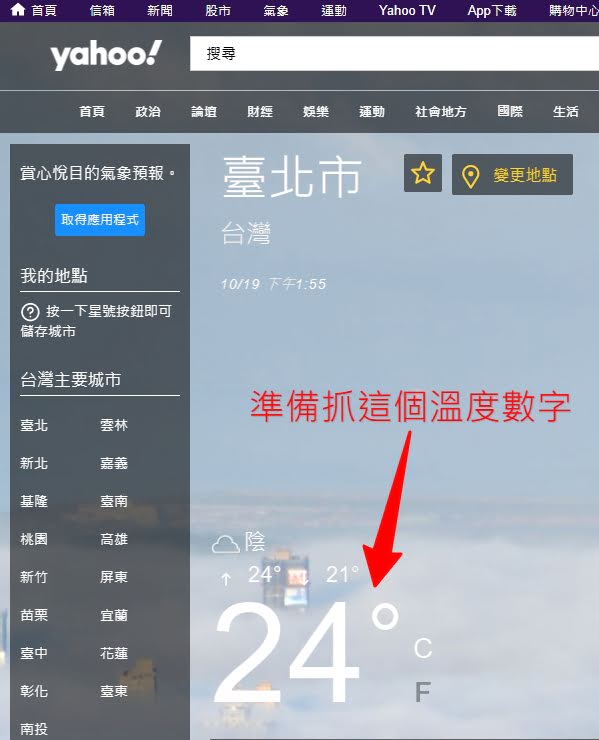
Step 2. 確定要擷取的氣溫後,開啟瀏覽器中的開發人員工具,找尋到要擷取HTML的目標區塊。
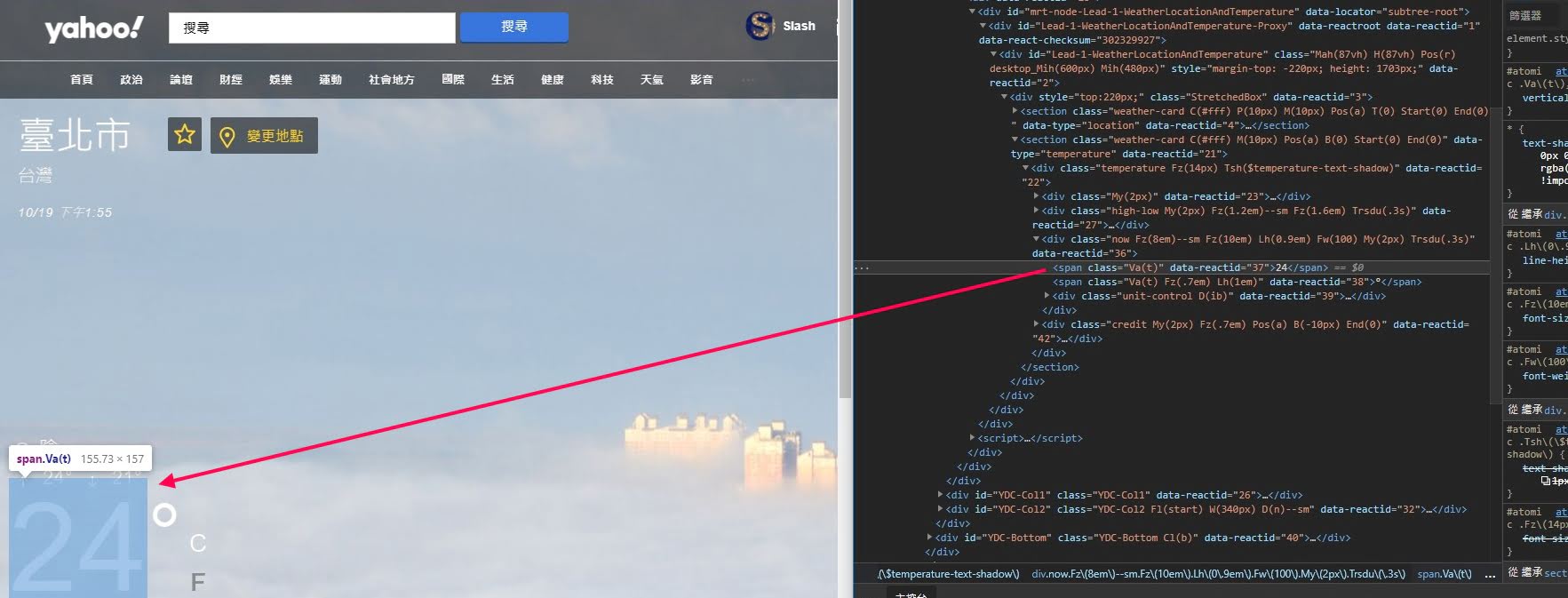
Step 3. 確定HTML的位置後,在該元素按下右鍵>複製>「複製XPATH」或「複製完整XPATH」。(一般來說「複製XPATH」會比較精簡,可讀性比較高)
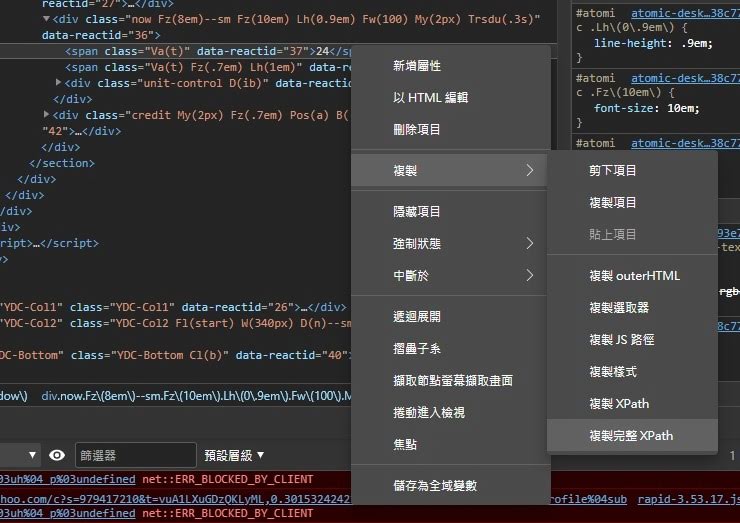
下方使用「複製XPATH」資訊來表示:
//*[@id="Lead-1-WeatherLocationAndTemperature"]/div/section[2]/div/div[3]/span[1]
Step 4. 接下來撰寫一段小程式碼來實證,大家可以從程式碼中看到Html Agility Pack類別方法包裝的其實非常精簡易懂。
var oHAP = new HtmlAgilityPack.HtmlWeb();
var oHTML = oHAP.Load("https://tw.news.yahoo.com/weather/%E8%87%BA%E7%81%A3/%E8%87%BA%E5%8C%97%E5%B8%82/%E8%87%BA%E5%8C%97%E5%B8%82-2306179");
string cTemperature = oHTML.DocumentNode.SelectSingleNode(@"//*[@id=""Lead-1-WeatherLocationAndTemperature""]/div/section[2]/div/div[3]/span[1]").InnerText;
WriteLine($"現在溫度:{cTemperature}");
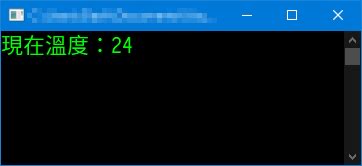
Step 5. 氣象溫度不費吹灰之力的被拿出來了。
XPath LIKE搜尋語法補充
在很多時候可能因為網站小改版,造成HTML階層異動而無法正確取用到資料,這時候XPATH的語法可能要寫得更彈性才不會跟隨對方網站版面的小異動而功能失效,舉例來說,基本上某關鍵區塊的CSS類別名稱不太可能會更動,因此我們或許可以用這樣的語法來下XPATH。
查詢某個HTML標籤之class類別名稱出現「ThisIsTemperatureBlock」:
//*[starts-with(@class, ""ThisIsTemperatureBlock"")]"